HPC
Overview
Oracle cloud supports High Performance Computing and makes it very easy to setup your own HPC cluster in the cloud. This tutorial here is a basic introduction to get your started.
This is a tutorial about SLURM on OCI with more background information: SLURM on OCI tutorial
You can find an alternative setup (tailored at deep learning and GPUs here: GPU cluster)
Before you get started
Consider if you actually need High Performance Computing (HPC) for your work. An HPC is a cluster consisting of multiple machines and it uses a head-node (here bastion host) from where jobs are submitted to this cluster using a job engine (for example slurm). If you have many jobs that need to be run independently than the setup described here will work well. A “real” HPC does more on top: There is a high-performance network between machines and it enables to run jobs that combine multiple machines (e.g. MPI). This would be needed if you have a problem that’s so large that a single machine wouldn’t be big enough. In this example here we build a cluster without this advanced networking. Most people will not need an HPC for their work and they should use a single virtual machine, because it requires considerably less setup work and easier to maintain.
Configure HPC cluster
Download the Terraform configuration from here as a zip file: https://github.com/oracle-quickstart/oci-hpc/releases/tag/v2.9.2
Make sure you selected the geographic region where you would like to create the resource (it should be close to you for best latencies).

Then go to Stacks under Resource Manager:
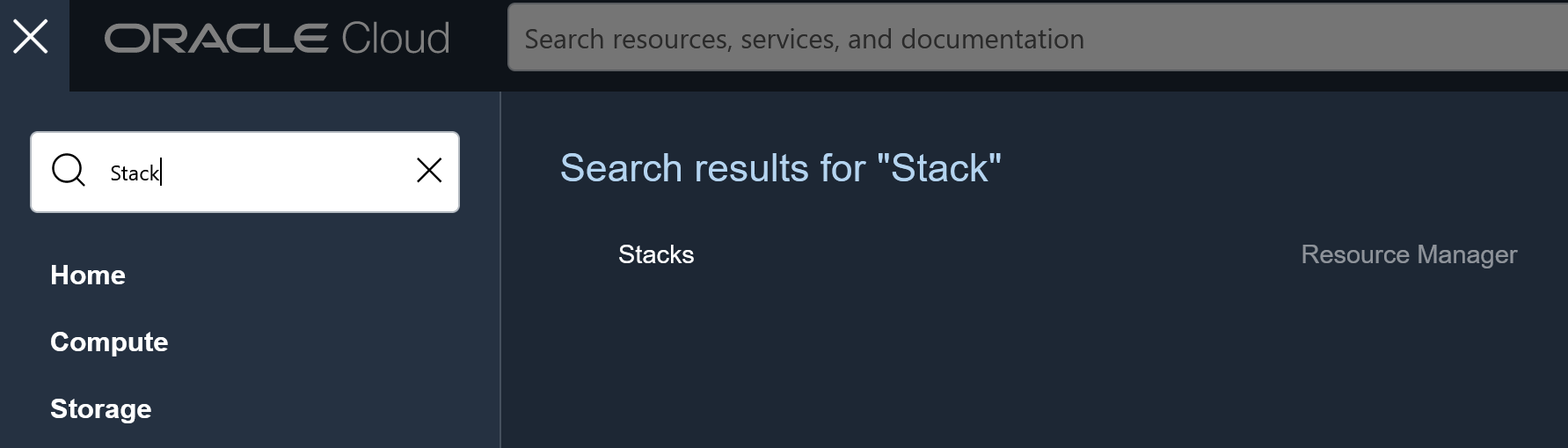
In the List Scope drop down menu, select your project compartment. Click Create Stack and upload the zip file as a Terraform configuration source.
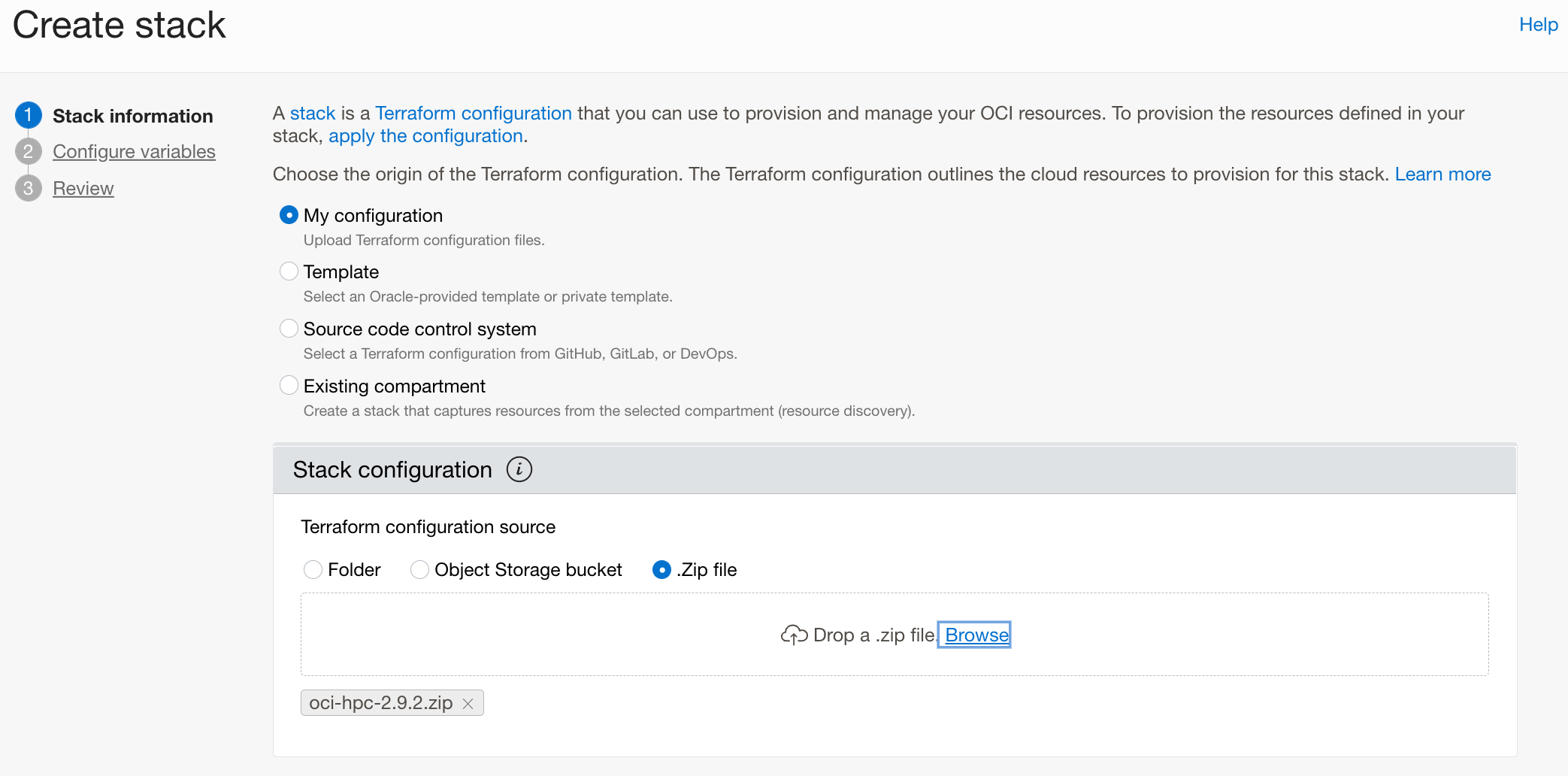
give your cluster a name, but leave the default options for the rest:
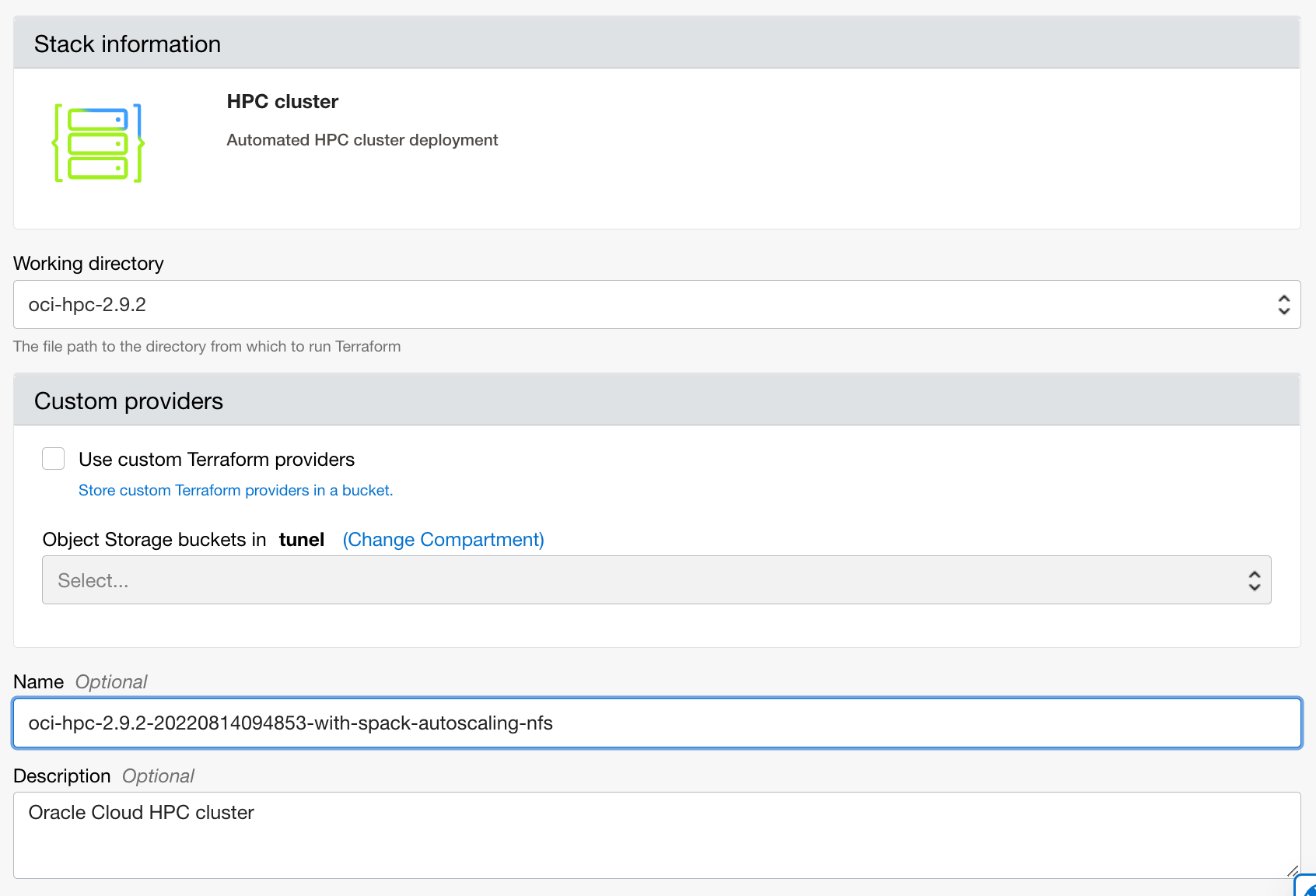
Check that the cluster is being created in your compartment again and then hit Next
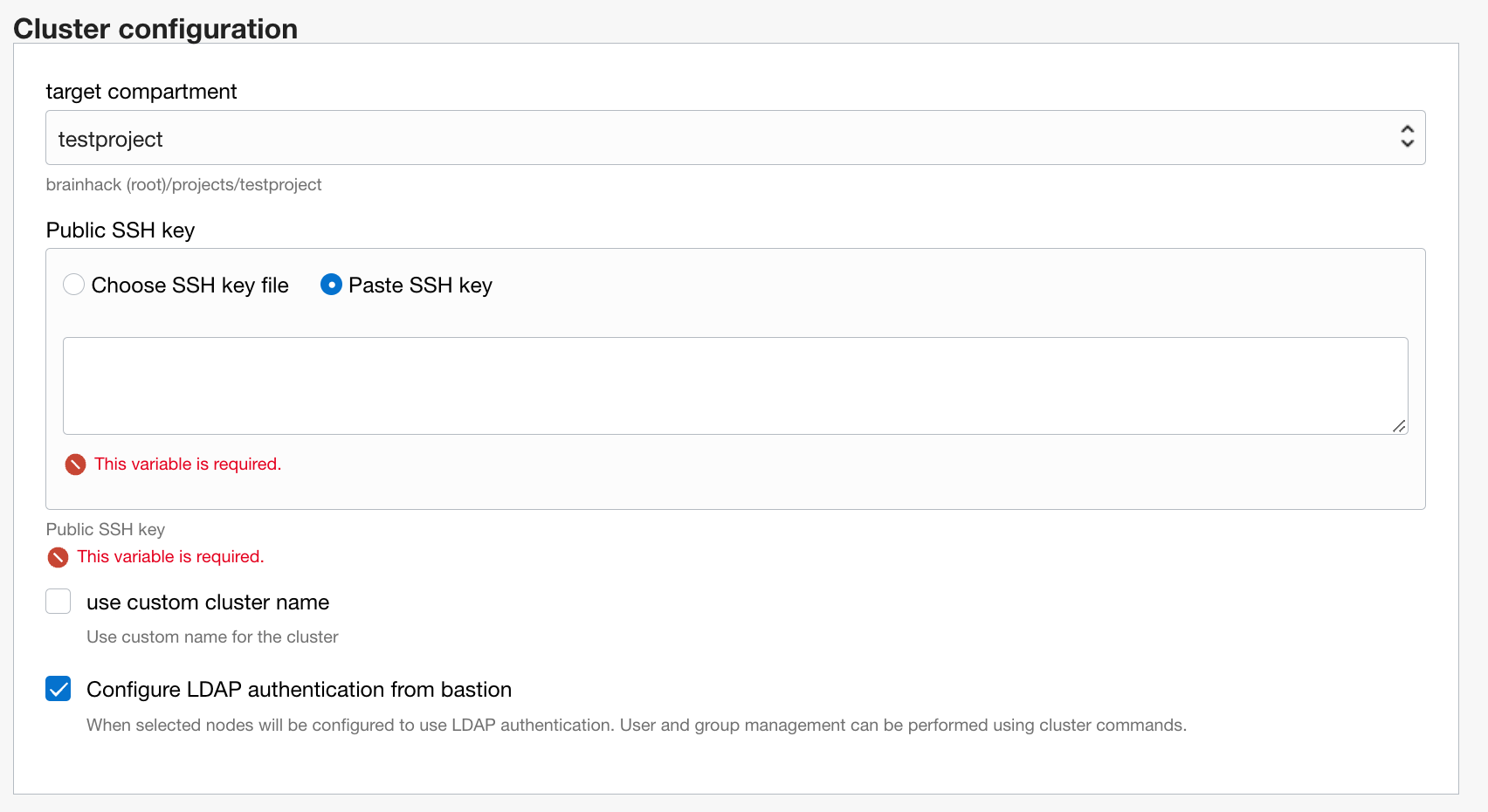
In cluster configuration you need to add your public SSH key for the opc admin account. Make sure to setup your SSH keys first create a public key
In Headnode options you need to select an Availability Domain. It doesn’t matter what you select there and the options will depend on the geographic region where you launch your HPC. You can keep the headnode default size, or you can select a different flavour:
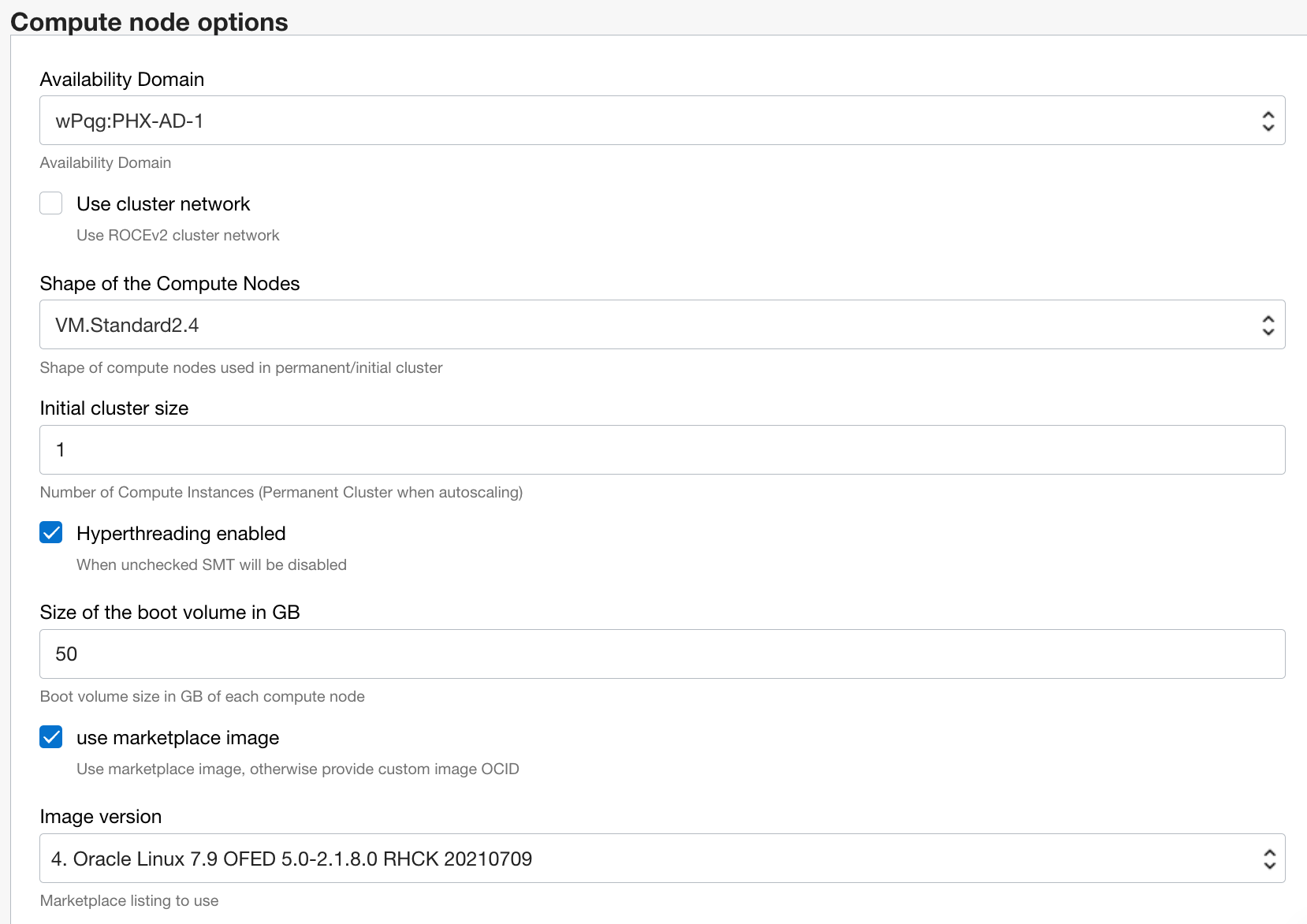
In Compute node options you need to disable Use cluster network (this is for MPI and not required for most people. It requires special network hardware that’s not available in every region. If you need MPI please get in touch and we can help you setting this up). Select a compute node size that fits your problem size. Drop the initial compute size node to 1, because we will scale the cluster using autoscaling.
In Autoscaling you should enable scheduler based autoscaling, monitor the autoscaling and disable RDMA latency check if you are not using MPI.

For API authentication and Monitoring leave the defaults:
For Additional file system accept the defaults:

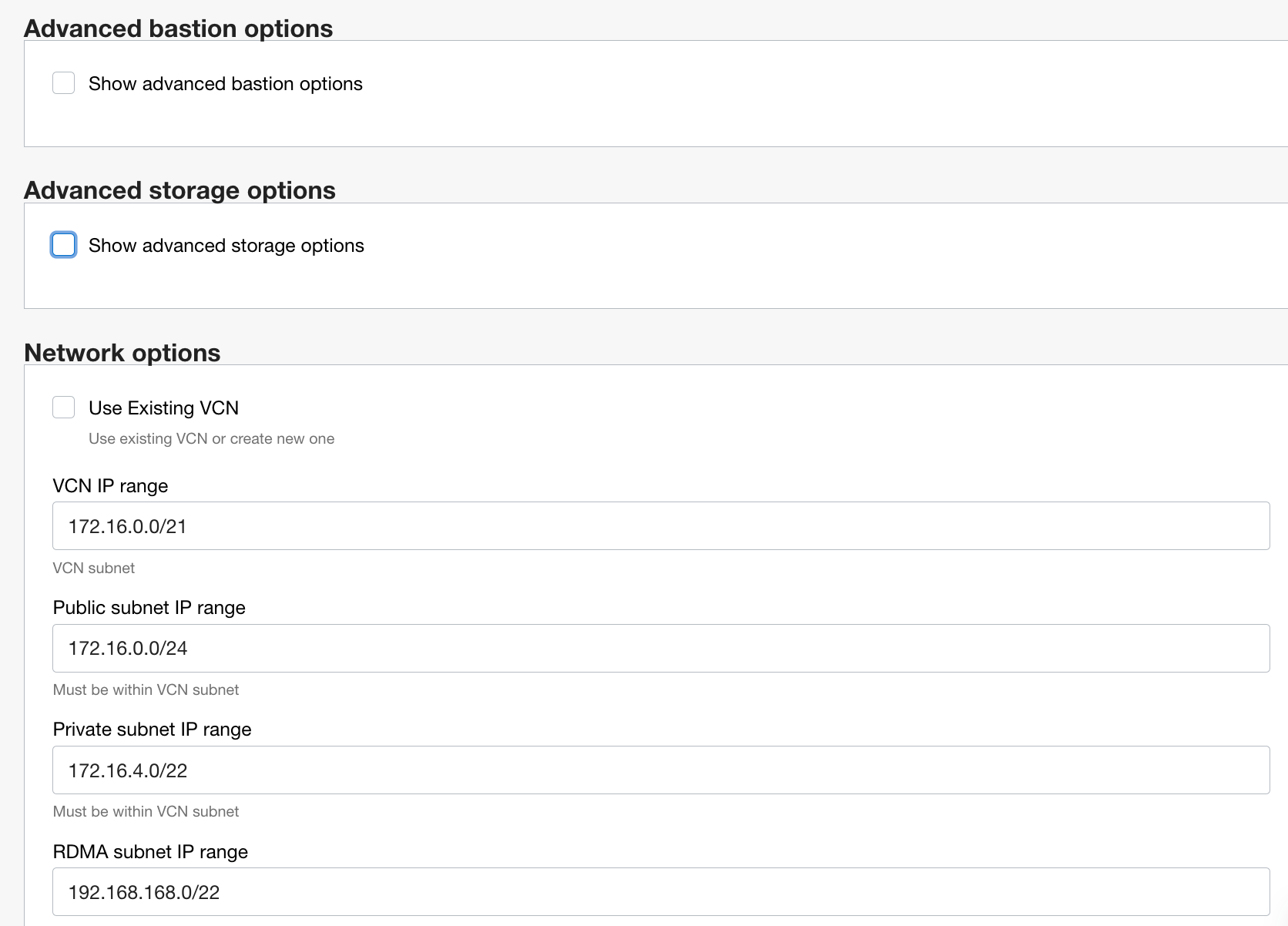
For Advanced bastion options, Avanced storage options and Network options you can accept the defaults:
For Software enable Install Spack package manager in addition to the defaults:
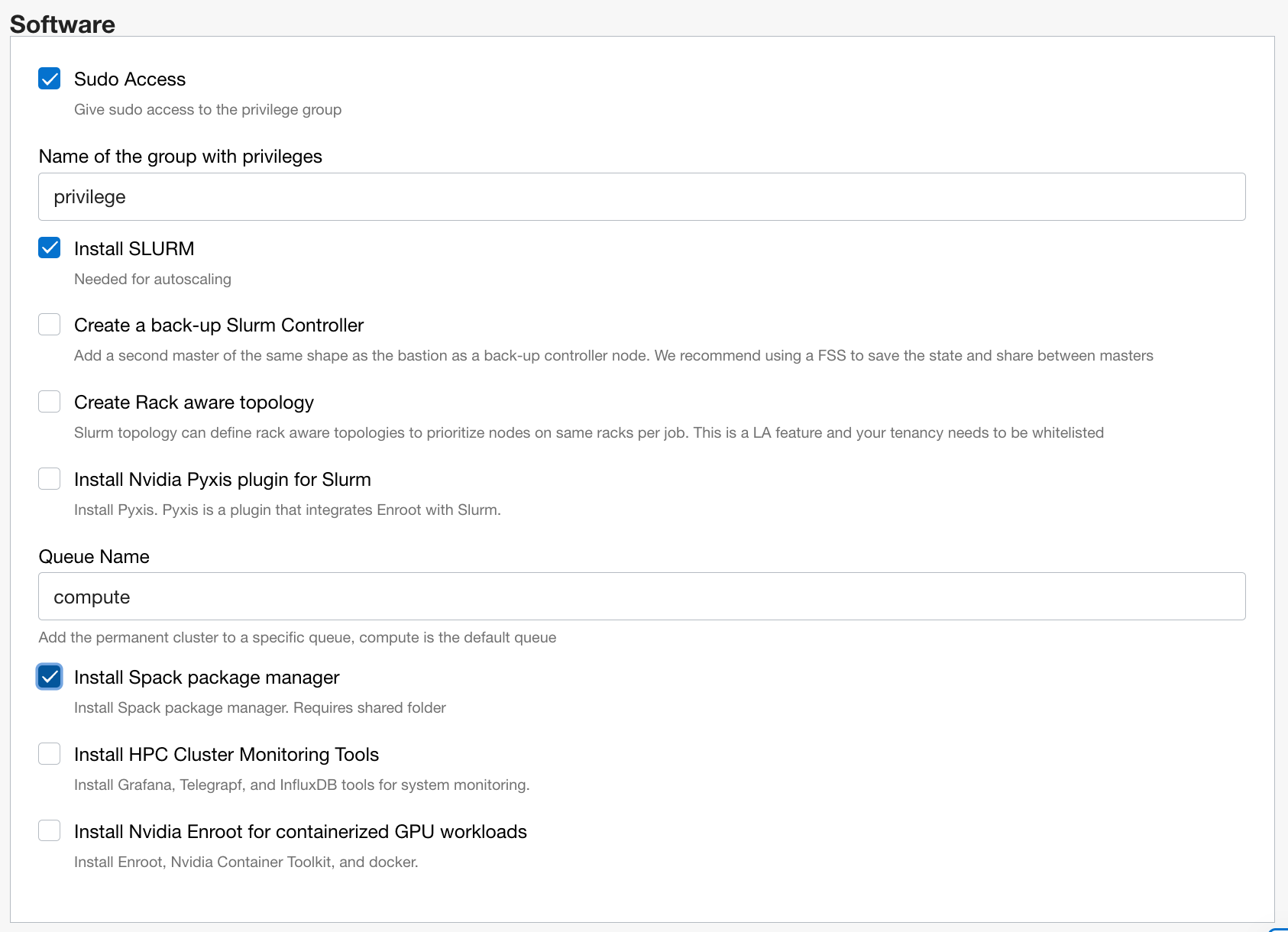
Then hit next and on the next page scroll to the end and tick Run apply:
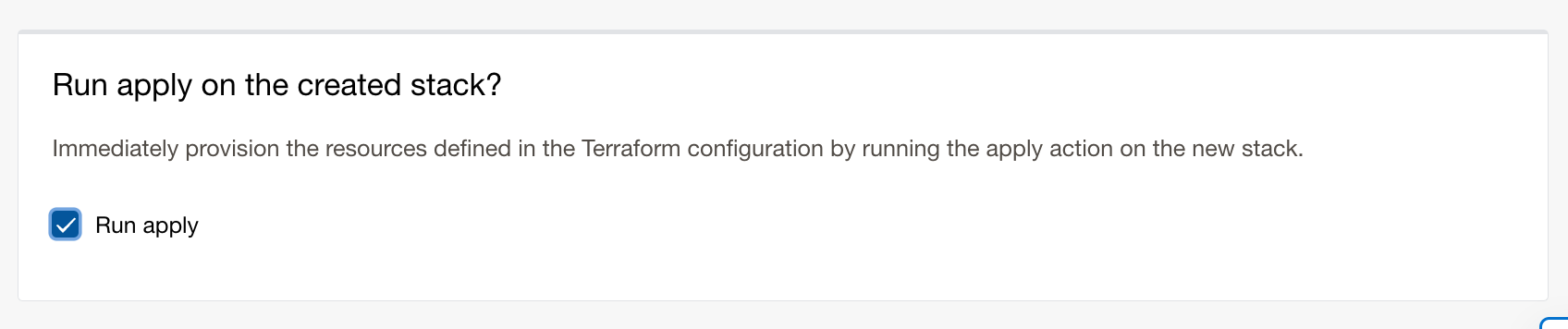
Then hit Create
This will then create a custom HPC for your project (it will take a couple of minutes to complete).
Once everything is done you find the bastion IP (the “head node” or “login node”) under Outputs:
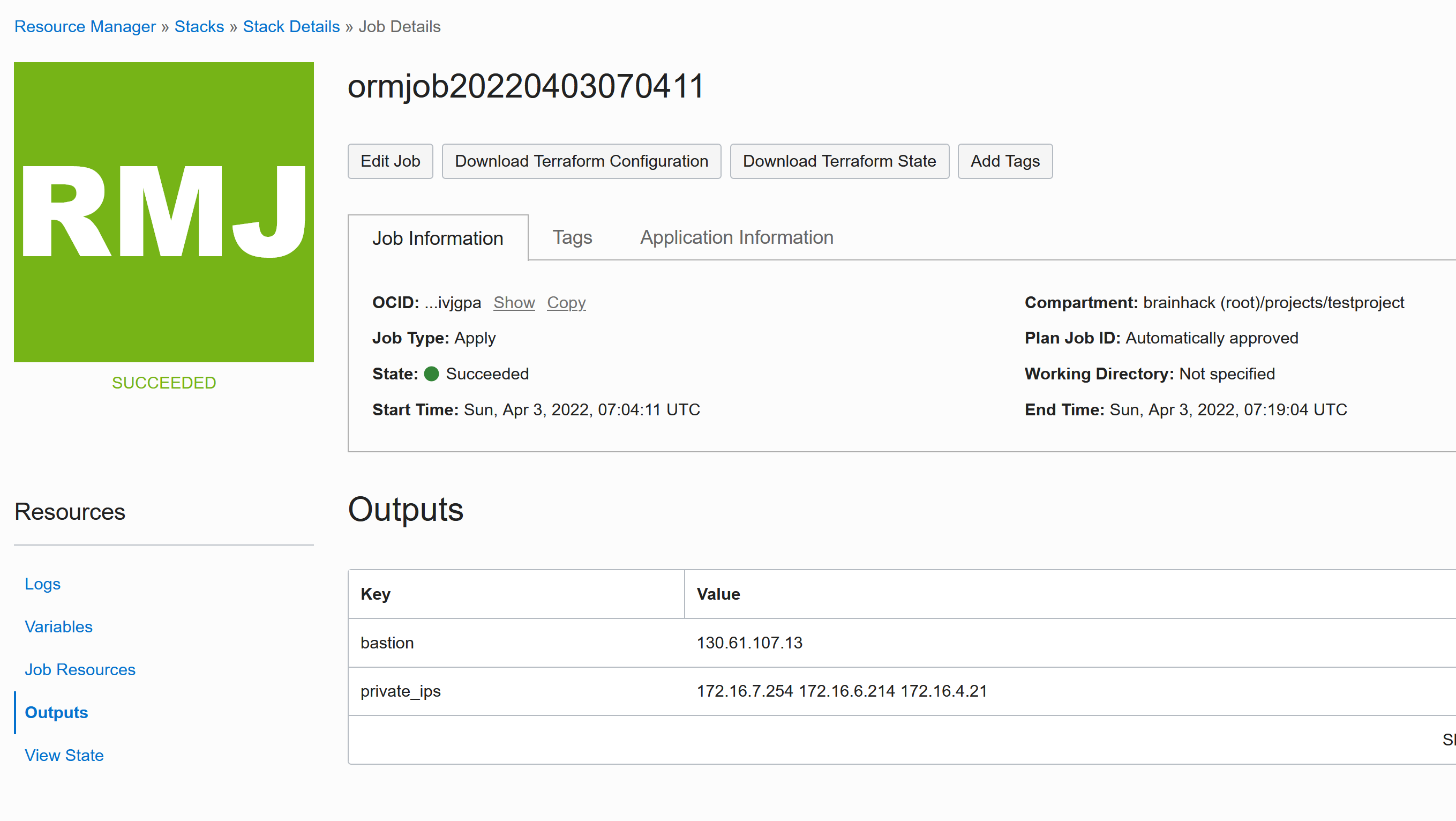
You can now ssh into the HPC as follows:
ssh opc@ipbastion
Be aware that this “opc” account is the admin account with sudo access of the cluster and should not be used to perform analyses. It is better to create a user account to perform the work in:
Once logged in with the opc account, you can create normal cluster users using the cluster command:
cluster user add test
These users can then login using a password only and do not require an SSH key.
There is a shared file storage (which can also be configured in size in the stack settings) in /nfs/cluster
More information can be found here: https://github.com/oracle-quickstart/oci-hpc
Configuring node memory
When you first submit jobs using sbatch, if you followed the above setup you may find you recieve the following error:
error: Memory specification can not be satisfied
This is happening as the RealMemory for each node (e.g. the amount of memory each compute node may use) has not yet been specified and defaults to a very low value. To rectify this, first work out how much memory to allocate to each node by running scontrol show nodes and looking at FreeMem.
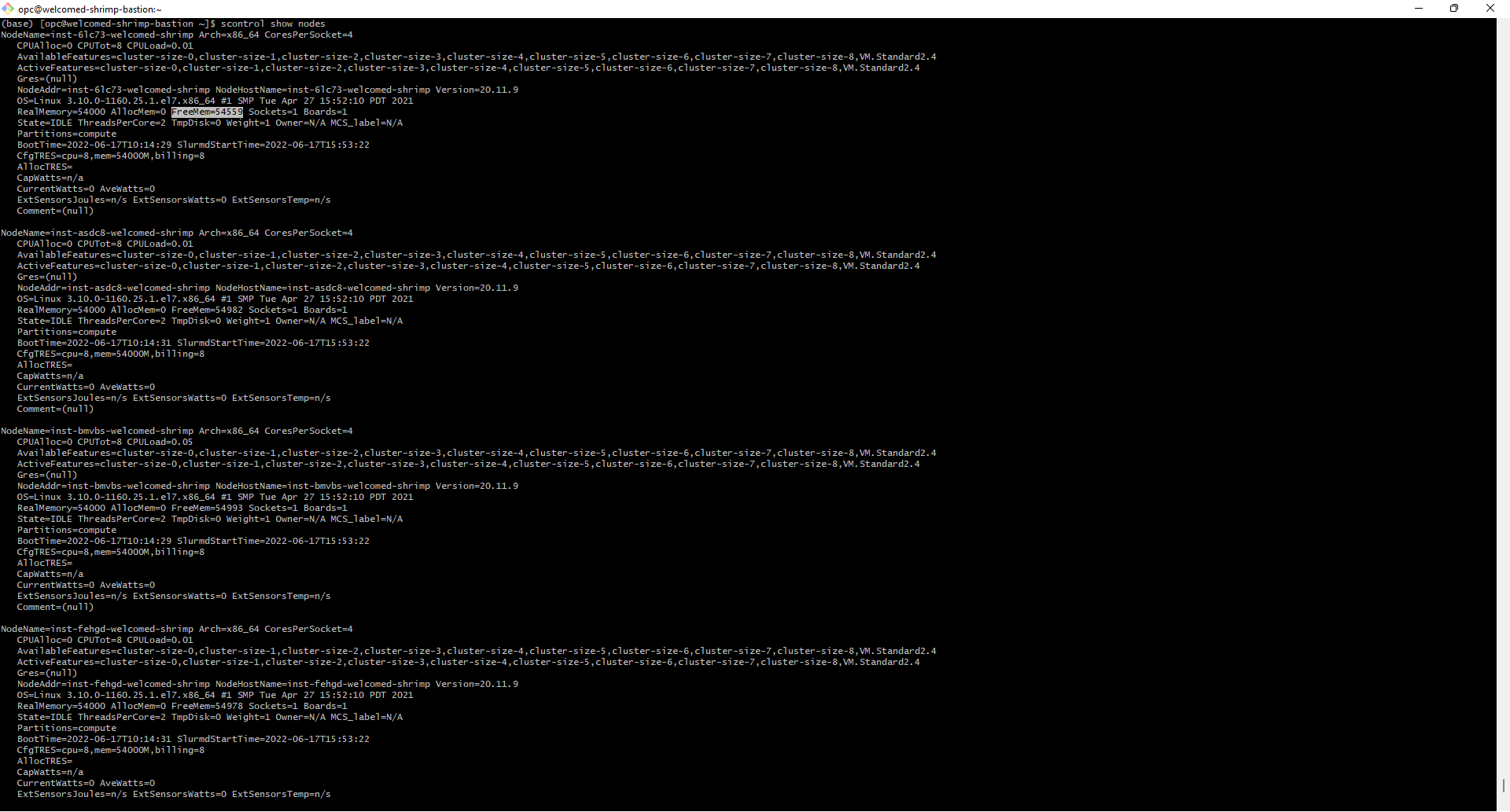
To change the RealMemory, you must edit the slurm configuration file (which may be found in /etc/slurm/slurm.conf). Inside the slurm configuration file you will find several lines which begin NodeName=. These specify the settings for each node. To fix the error, on each of these lines, add RealMemory=AMOUNT where AMOUNT is the amount of memory you wish to allow the node to use.
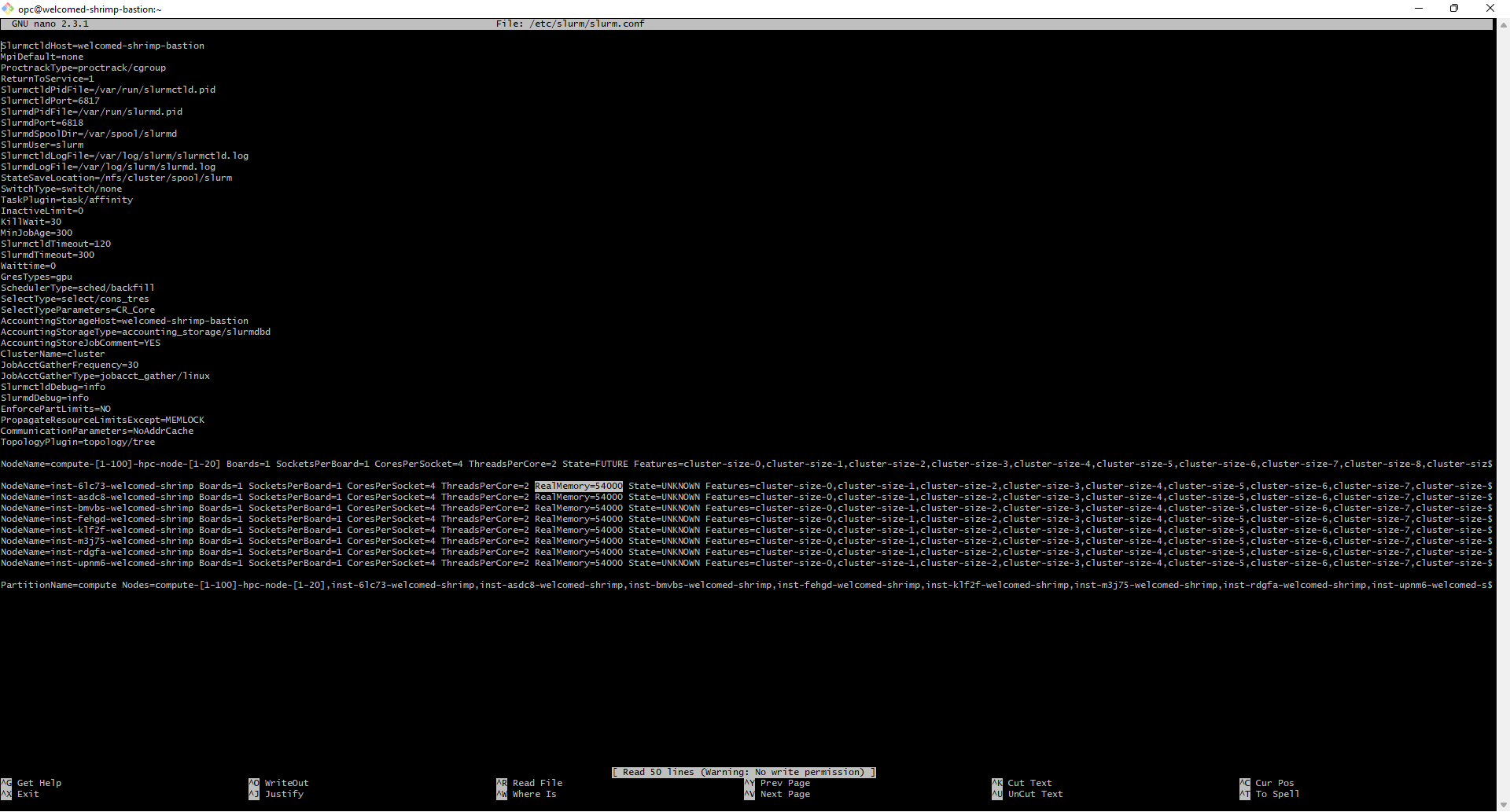
Once you have done this, you must reconfigure slurm by running the following command:
sudo scontrol reconfigure
Configuring X11 forwarding
If you want to use graphical aplications you need to install:
sudo yum install install mesa-dri-drivers xorg-x11-server-Xorg xorg-x11-xauth xorg-x11-apps mesa-libGL xorg-x11-drv-nouveau.x86_64 -y
sudo vi /etc/ssh/sshd_config
change to:
X11Forwarding yes
X11UseLocalhost no
then
sudo systemctl restart sshd
# or
sudo service sshd restart
For full functionality, you may also need to add PrologFlags=X11 to your /etc/slurm/slurm.conf, along with enabling the following
additional parameters in you /etc/ssh/sshd_config:
AllowAgentForwarding yes
AllowTcpForwarding yes
X11Forwarding yes
X11DisplayOffset 10
X11UseLocalhost no
On you main node, to restart slurm:
```console
sudo slurmctld restart
And on your worker nodes:
sudo service slurmd restart
After you’ve updated slurm, you can confirm the Prolog setting has taken:
sudo scontrol reconfigre; sudo scontrol show config | grep PrologFlags
And also check that x11 works!
srun --x11 xeyes
Troublehsooting: Editing a deployd stack fails
This can have many reasons, but the first one to check is:
Error: 409-Conflict, The Instance Configuration ocid1.instanceconfiguration.oc1.phx.aaaaaaaabycbnzxq4uskt4f7mklp4g4fcqk4m42aabj2r2fkchjygppdudua is associated to one or more Instance Pools.
This means that the Instance Pool blocks the terraform script. To get it back working you need to destroy the stack first and then rebuild it.
Another option is that the resource type you used is not supported:
Error: 400-InvalidParameter, Shape VM.Standard1.4 is incompatible with image ocid1.image.oc1..aaaaaaaamy4z6turov5otuvb3wlej2ipv3534agxcd7loajk2f54bfmlyhnq
Suggestion: Please update the parameter(s) in the Terraform config as per error message Shape VM.Standard1.4 is incompatible with image ocid1.image.oc1..aaaaaaaamy4z6turov5otuvb3wlej2ipv3534agxcd7loajk2f54bfmlyhnq
Here, I selected a shape that is too “small” and it fails. It needs at least VM.Standard2.4
Installing Custom Software
If you don’t want to use spack (or cannot) then a good strategy is to install under /nfs/cluster, add any relevant “bin” directories it to your path, and install there.
As an example we will install go:
$ cd /nfs/cluster
$ wget https://go.dev/dl/go1.19.linux-amd64.tar.gz
$ sudo tar -C /nfs/cluster -xzf go1.19.linux-amd64.tar.gz
$ rm go1.19.linux-amd64.tar.gz
And then add the go bin to your bash profile (vim ~/.bash_profile) as follows:
export PATH=/nfs/cluster/go/bin:$PATH
and when you open a new shell or source ~/.bash_profile you should be able to see go on your path:
$ which go
/nfs/cluster/go/bin/go
$ go version
go version go1.19 linux/amd64
Further, since it’s located in the /nfs/cluster directory, it will be available on other nodes! Here is how to see the other nodes you have:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
compute* up infinite 1 idle compute-permanent-node-941
And then shell into one, and also find the go binary.
$ ssh compute-permanent-node-941
Last login: Sun Aug 14 02:30:01 2022 from relative-flamingo-bastion.public.cluster.oraclevcn.com
$ which go
/nfs/cluster/go/bin/go
Install Singularity
First, system dependencies. Follow the example above in install custom software to install Go. Next, install Singularity dependencies. These will need to be installed to each node.
sudo yum groupinstall -y 'Development Tools'
sudo yum install libseccomp-devel squashfs-tools cryptsetup -y
sudo yum install glib2-devel -y
Ensure Go is on your path (as shown above). Then install Singularity. We will install from source.
Important ensure you don’t have anything (e.g., pkg-config) loaded from spack, as this can interfere with installing Singularity using system libs. Also note that installing with system libs is a workaround for spack singularity not working perfectly (due to setuid). This means you’ll need to do these steps on each of your head login and worker nodes.
You can do the same with an official release. Note that you don’t need to compile this on the nfs node - you can compile it anywhere and make install to /nfs/cluster.
$ git clone https://github.com/sylabs/singularity
$ cd singularity
$ git submodule update --init
# You can also set prefix to be it's own directory, e.g., /nfs/cluster/singularity-<version>
$ ./mconfig --prefix=/nfs/cluster
$ cd ./builddir
$ make
$ make install
Once you install, make sure you add the newly created bin to your path (wherever that happens to be). E.g., that might look like:
export PATH=/nfs/cluster/go/bin:/nfs/cluster/bin:$PATH
And then when you source your ~/.bash_profile you can test:
$ which singularity
/nfs/cluster/bin/singularity
Advanced: Use MPI networking
Your first need to request access to those resources with this form.
Then follow the above instructions, but leave Use cluser network activated and RDMA options enabled.